
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 음수와 size 비교
- 코테준비
- Ai
- 모델링
- 알고리즘
- 코딩
- 코테
- 코테공부
- 상어중학교
- 머신러닝
- 취준
- kt에이블스쿨
- map
- 프로그래머스
- 크롤링
- dfs
- C++
- 21609
- 개인정보수집유효기간
- 스터디
- 파이썬
- 코테연습
- 데이터전처리
- python
- 미니프로젝트
- 에이블스쿨
- 코딩테스트
- 백준
- Queue
- BFS
- Today
- Total
얼레벌레
[7주차] AI 모델 해석 및 평가 본문
| 1일차 | 모델 해석 |
| 2일차 | 모델 평가 |
AI 모델 해석과 평가가 필요한 이유
AI 모델을 하는 이유는 비즈니스 문제를 해결하기 위해서였다.
그럴려면 누군가가 모델에 대해서 왜 그런지, 비즈니스 문제를 해결할 수 있는지 의문을 제기했을 때 대답할 수 있어야 한다.
- 인식 전환 : 모델이 왜 그렇게 예측했는가?
- 모델이 비즈니스 문제를 해결할 수 있는가?
이 문제들에 대한 대답을 찾기 위해 AI 모델 해석과 평가가 중요하다.
Interpretability vs Explainability
Interpretatbility : 해석, input에 대해 모델이 왜 그런 output을 예측했는가?
(whitebox model은 본질적으로 해석가능)
Explainability : 설명, 추가로 투명성에 대한 요구, 모델이 어떻게 학습 되는지 단계별로 설명이 가능해야 함(model transparency)
+ 설명이 잘 되는 알고리즘은 대체로 성능이 낮다.
모델에 대한 설명
- Feature Importance (변수 중요도) : 모델 전체에서 어떤 feature가 중요?
- Partial Dependence Plot (PDP) : 특정 feature 값의 변화에 따라 예측값은 어떻게 달라질까?
- Shapley Additive Explanation(SHAP) : 이 데이터(분석단위)는 왜 그러한 결과로 예측되었을까?
이 모든 것은 모델 최적화가 전제조건이다. (모델 해석과 설명은 튜닝이 먼저)
변수 중요도
알고리즘 별 내부 규칙에 의해, 예측에 대한 변수 별 영향도 측정 값.
성능이 낮은 모델에서의 변수 중요도는 의미 없음.
모델에서 Feature Importance를 제공하는 알고리즘 : Tree 기반 알고리즘들 (DT, RF, XGB 등)
+ 변수 중요도를 제공안하는 모델에서도 어떻게든 뽑아내야 함.
- Decision Tree 에서의 Feature Importance
- Mean Decrease Impurity (MDI)
전체 Tree에 대해서, 각 변수 별로 Information Gain의 가중평균을 계산한다.
- Mean Decrease Impurity (MDI)
- Random Forest 에서의 Feature Importance
- Mean Decrease GINI
개별 트리의 MDI로부터, 각 변수 별 importance의 평균을 계산
개별 트리의 변수중요도로부터 평균을 구해 랜덤 포레스트의 변수중요도를 구함
- Mean Decrease GINI
- XGB에서의 Feature Importance
구하는 데는 3가지 방법이 있다.- weight : 모델 전체에서 해당 feature가 split될 때 사용된 횟수의 합
plot_importance 에서의 기본 값 - gain : 각 feature 별 평균 information gain
model.feature_importances_ 의 기본 값
total_gain은 각 feature 별 information gain의 총 합이다. - cover : feature가 split할 때 샘플 수의 평균 (얼마나 많은 데이터를 분할하는지)
total_cover은 샘플 수의 총 합
- weight : 모델 전체에서 해당 feature가 split될 때 사용된 횟수의 합
- Permutation Feature Importance : 순열을 기반으로 한 feature importance
feature 하나의 데이터를 무작위로 섞을 때, model의 score가 얼마나 감소되는지로 계산한다.
(섞지 않을 때와 섞었을 때의 성능을 비교한다.)
=> feature 하나의 순서가 바뀌면 score가 바뀌는데, 많이 바뀔수록 중요도가 높은 변수이다. (영향이 높으니까)- 중요도 i(j) = s - 1/K * (s(k, j)의 합)
s는 원본 score , K는 섞는 횟수, s(k, j)는 j번째 변수를 k번째 섞을 때의 score - 단점: 다중공선성이 있는 변수가 있을 때, 특정 변수 하나가 섞이면 관련된 변수는 그대로 있음 => score가 별로 줄지 않음
- 코드
from sklearn.inspection import permutation_importance
pfi1 = permutation_importance(model1, x_val_s, y_val, n_repeats=10, random_state=2022)
model1 : 알고리즘 상관 없음
n_repeats : 반복횟수 (10번 반복) - 결과
importances : 각 변수별 반복횟수만큼 계산된 score
importances_mean : 변수 별 score의 평균
importances_sdt : 변수 별 표준 편차 - 시각화 : kde plot, bat plot
- 중요도 i(j) = s - 1/K * (s(k, j)의 합)


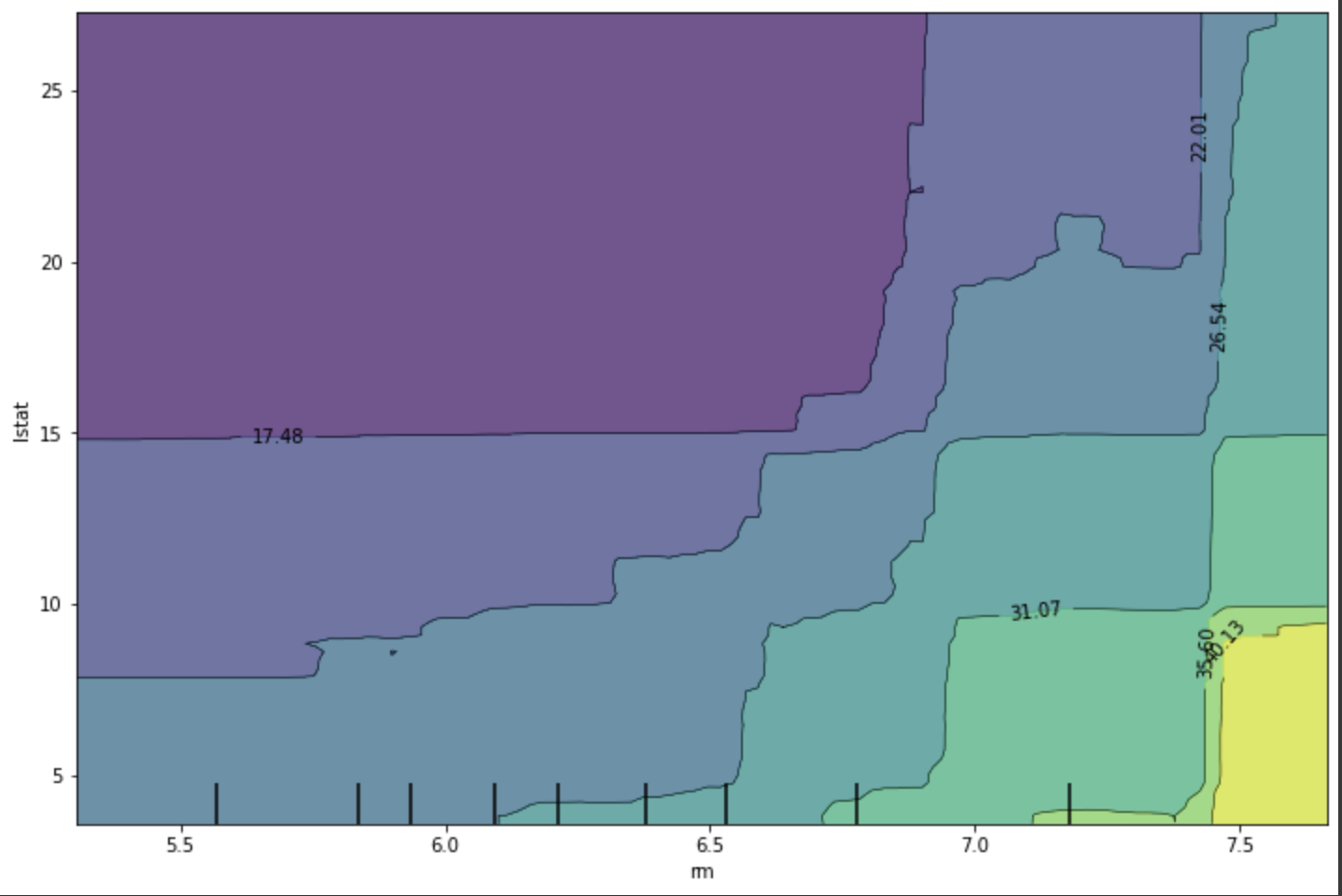
PDP (Partial Dependence Plots)
- 관심 feature의 값이 변할 때, 모델에 미치는 영향을 시각화
- feature 값의 종류가 6.2, 8.4, 8.9 3가지라면
- 데이터 셋의 해당 feature 값을 모두 6.2로 바꾼 후 예측값들을 뽑아 평균을 계산한다.
- 8.4와 8.9에 대해서도 같은 작업을 하고, 그래프를 그린다.
- 코드
from sklearn.inspection import plot_partial_dependence
plot_partial_dependence(model, features=['rm'], X=x_train, kind='both')
kind='both'는 개별 instance와 average값을 함께 그리는 옵션 - 결과 그래프에서 경향을 파악할 수 있다. (x축은 해당 feature, y축은 target값)

- 두 feature와 예측 결과와의 관계

SHAP (SHapley Additive exPlanations)
- 가중평균을 가지고 왜 그렇게 예측했는지 설명하는 방법
ex) 데이터 한 건에 대해서 집값을 예측했더니 30만 유로, 모든 아파트의 평균 예측값은 31만 유로라고 했을 때
-1만 유로 차이에 각 feature들이 어떤 기여를 했는지가 궁금. - Shapley value : 모든 가능한 조합에서, 하나의 feature에 대한 평균 기여도를 계산한 값.
- 각 조합을 구함 (target 변수는 고정시켜놓고, 나머지 변수들로 조합을 구성)
- 각각의 조합에 대해서 모델1을 만들어 예측 (.predict에 조합을 넣어 모델을 만듦)
- 조합에서 특정 feature을 뺀 예측값으로 모델2를 만들어 예측
- 모델1의 예측값과 모델2의 예측값의 차이가 그 feature의 기여도
- 각 feature 별로 구한 기여도를 바탕으로 가중평균 구하기 => 결과가 shapley value
(가중평균은 가중치*값의 합으로 구함)
- 코드
# 모델 생성
model1 = RandomForestRegressor()
model1.fit(x_train, y_train)
# 생성된 모델로 Explainer 만들고, 특정 데이터 셋에 대해 shapley value 추출
explainer1 = shap.TreeExplainer(model1)
shap_values1 = explainer1.shap_values(x_train)
x_train.shape, shap_values1.shape #같은 결과 - 시각화
- shap.force_plot
전체 평균을 중심으로 예측된 값에 어떠한 영향을 주었는지 변수 별로 확인 (상승요인:빨강, 하락요인:파랑)
similarity 선택하면 shap value에 대해 클러스터링하고 나서 정렬 - shap.summary_plot
feature 별 전체 shapley value 시각화 - shap.dependence_plot
특정 feature과 shap value의 관계 (scatter) - 외에도 많은 plot 함수가 있다.
- shap.force_plot
타겟 마케팅
ML Metric 의 의미
Regression : 수요량 예측 모델을 만들었는데, RMSE가 줄었다. 개선된걸까?
Classification : 기계고장 예측 모델을 만들었는데, f1score가 올랐다. 개선된걸까?
=> 모델 성능은 좋아졌지만, 비즈니스 관점에서도?
Q. 어떤 문제를 해결하기 위해 모델을 만들었는가? => FI, PFI, PDP, SHAP
Q. 실제 목적에 맞게 모델의 결과를 평가하고 있는가?
Q. 모델의 예측 겨로가에 대한 현장의 비즈니스 프로세스는 어떻게 정의되어 있는가?
타겟 마케팅
매스 마케팅 : 불특정 다수 고객 대상
타겟 마케팅 : 특정 고객 대상
프로모션에 응할 확률을 P(x),
그 때의 비즈니스 가치 V1,
응하지 않았을 때의 비즈니스 가치를 V0이라고 정의하면
기대가치 = P(x) * V1 + (1-P(x)) * V0
=> 기대가치가 0보다 커야 이익
- 모델 예측 결과를 비율로 변경
Positive Negative 프로모션에 응한 사람 40 => 0.04 10 => 0.01 응하지 않은 사람 220 => 0.22 730 => 0.73 - 비즈니스 가치 matrix 계산 (상품 판매가 20000원, 매입원가 10000원, 프로모션 비용 상품 개당 200원이라고 가정)
Positive Negative 프로모션에 응한 사람 9800 (20000-10000-200) 0 (기회비용 생각하지 않음) 응하지 않은 사람 -200 0' - 모델 기대가치 계산 : 위의 매트릭스 두개를 곱해서 구함
=> 예측 기반 프로모션을 통한 1인당 예상 수익액 : 348원Positive Negative 프로모션에 응한 사람 392 0 응하지 않은 사람 -44 0
=> 이 때부터 목표는 348원을 높이는 것이 됨. (348원을 가장 높이는 모델 만들기가 목표)
모델을 통해 예측 결과를 뽑게 되면, 그 결과를 활용해 이후 업무 절차 전개를 정의해야 한다.
=> 그걸로 비즈니스 평가에 대한 방안 도출
'취업 > KT AIVLE SCHOOL' 카테고리의 다른 글
| [8주차] 딥러닝 (1) | 2022.09.22 |
|---|---|
| [7주차] 에이블데이 (1) | 2022.09.12 |
| [6주차] 미니프로젝트 2차 (0) | 2022.09.12 |
| [5주차] 시계열 분석 (1) | 2022.09.12 |
| [5주차] 머신러닝 모델링 - 성능 (0) | 2022.09.12 |

